서론
이전의 두개의 글에서 설명한 TorchModelArchiver와 TorchServe를 알았다면 이제는 Kserve를 이용해 실제로 pytorch 모델을 서빙해 볼 차례이다!
본론
필요성
TorchServe가 있는 굳이 Kserve를 사용해야 하는 이유는 뭘까? TorchServe 가 제공하는 기능 외에 어떤 기능이 있나?
- 쿠버네티스의 스탠다드 모델 추론 플랫폼으로, Knative Serving를 활용해 서버리스를 포함한 스케일링 기능을 제공한다.
- Istio와 Knative Serving의 조합으로 카나리 롤아웃, 앙상블, 트랜스폼 등 진보된 배포를 제공한다.
중요 개념
kserve 를 이해하기 위해서는 먼저 Control Plane, Data Plane 을 이해해야 한다.
Control Plane: 추론을 담당하는 커스텀 리소스를 관리한다.
InferenceService커스텀 리소스 조정을 담당하는 역할을 한다.- knative 서버리스 배포를 지원하여 오토스케일링이 가능케 한다. KServe를 Knative Serving 없이 사용할 수 있는 raw 배포 모드가 활성화되면, 컨트롤플레인은 deployment, service, ingress, HPA 을 생성한다.(scale-to-zero는 지원하지 않는다)
- Control Plane의 핵심은 KServe Controller인데, service, ingress resources, model server container and model agent container(요청/응답 로깅, 배칭이나 모델 풀링 기능) 를 만드는 역할을 한다.
- 구조는 아래와 같다

Data Plane: 특정 모델을 대상으로 하는 요청/응답 주기를 관리한다
- REST 요청을 endpoint 로 전달하고, Transformer, Explainer, Predictor를 거쳐서 client가 결과를 받게 된다 (predictor만 필수다)
- KServe는 두 버전을 제공한다. V1 프로토콜은 스탠더드 추론 워크플로를 HTTP/REST 로 제공한다. V2는 기존의 V1의 performance 나 generality 같은 문제를 개선했고,gRPC APIs 로 기능을 더했다. 둘의 기능에 대한 상세설명 페이지 를 참고 하도록 하자.
- 구조는 아래와 같다
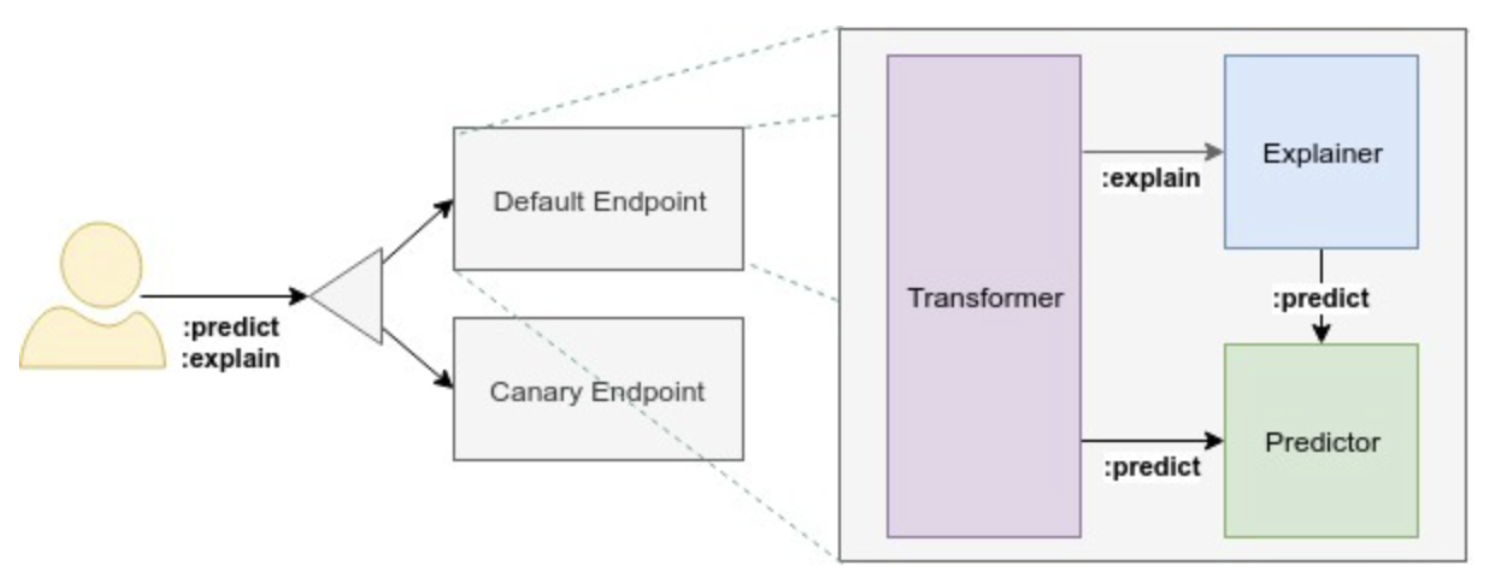
지금까지 공식문서에서 설명하는 두가지 개념을 알아봤는데 뭔가 와닿지 않는다...
그리고 가장 와닿지 않는 점은 InferenceService 를 정의하면 추론 서비스가 자동으로 뜨게 되는데, 어떻게 실제로 동작하는지에 대해 알고 싶어졌다
내부 동작 원리
사실 이부분은
조금
많이 틀린 부분이 있을 수 있다. 필자는 go와 custom controller에 대해 자세히 모르는 상태에서 controller의 go 코드를 봤기 때문이다.. 필자의 공부 수준과 뇌피셜에 의존하니 틀린점을 언제든지 댓글로 남겨주시면 감사하겠다.
아무튼.. 위에서 설명한 것처럼 InferenceService 를 작성하고 kubectl apply -f <파일명> 을 하면 서비스가 떠서 해당 서비스에 추론을 실행해보는 예시를 쉽게 찾아 볼 수 있을 것이다. 하지만 이게 어떻게 이렇게 동작하는지가 명확하지 않았다. 그러면 대체 어떻게 동작하는 것인가!?
(1) 우선 Control Plane의 그림을 보면 InferenceService 에 reconcile이라는 화살표가 Kserve Controller로 간다. 즉, InferenceService 라는 CR이 생성되면, 이를 바라보고 있는 CC가 Kserve Controller 인 것이다. 그래서 Kserve Controller 의 InferenceService 의 reconcile 부분 코드 를 보니 중간에 NewPredictor, NewTransformer, NewExplainer 를 넣는 부분이 보였다. 그리고 그보다 조금 아래서 리스트로 받은 reconcilers 를 reconcile 하는 부분이 보였다. 즉, 각각의 리소스가 reconcile 되는 것이다.
-> InferenceService 리소스가 생성되면 KServe Controller reconcile 코드에서 NewPredictor, NewTransformer, NewExplainer 가 reconcile 된다.
(2) 그래서 reconcile 되면 내부적으로 어떤 일이 일어나는지 확인해 보기 위해서 NewPredictor, NewTransformer, NewExplainer 이 셋 중 하나인 Predictor 의 reconcile 코드로 가보았다. InferenceService 에서 받은 내용을 기준으로 ServingRun 을 설정하고, podSpec 도 설정하고 svc 도 만들고 기타 등등을 하고, deployment를 생성한다. 그러면 정의된 내용으로 pod가 생기는 것이었다.
-> reconcile을 통해 설정값들을 설정하고, deployment를 생성하면, deployment 를 보고 k8s controller는 이에 맞는 pod 를 띄운다.
(3) 그리고 이때 modelFormat.name을 pytorch로 하면 디폴트 클러스터링 서빙런타임으로 제공되는 타입중 kserve-torchserve가 실행되고, 이 컨테이너에서는 torchserve --start --model-store=/mnt/models/model-store --ts-config=/mnt/models/config/config.properties 로 컨테이너를 실행 시키는 것을 확인 할 수 있다.
-> Predictor 의 reconcile 에서 특정 ServingRun 을 설정하고 deployment 를 생성하면 해당 ServingRun 도커로 pod 가 뜨는데, 이 도커의 내부 실행 명령어가 torchserve --start --model-store=/mnt/models/model-store --ts-config=/mnt/models/config/config.properties 이다. 그러면, pod 내에 torchserve가 뜨게 되는 것이고, 이는 외부에서 REST API로 접근이 가능하다.
(4) 이것을 통해 첫번째 포스트 TorchModelArchiver에서 만든 .mar 파일은 --model-store=/mnt/models/model-store 에 놓고, 두번째 포스트 TorchServe에서 만든 config.properties 파일은 /mnt/models/config/config.properties 에 놓아야 함도 알 수 있다.
(5) 만약 디폴트가 아닌, custom ServingRuntime 을 사용하고 싶다면, KserveTornado 혹은 KserveFlask 를 상속받아 클래스를 만들고, 해당 객체를 인스턴스화(runtime)하여 runtime.app.run(debug=True, port=8080) 을 실행한 코드를 넣은 도커 이미지를 만들고, InferenceService 에서 이 custom ServingRuntime 사용하도록 명시해주면 된다. 그러면 해당 도커로 pod가 뜨고, 내부적으로는 이전과 동일하게 torchserve --start --model-store=/mnt/models/model-store --ts-config=/mnt/models/config/config.properties 가 실행 될 것이다.
(6) 동작 원리를 끝내기전 ServingRuntime 에 대해 아는 선에서 조금만 더 설명을 해보면, ServingRuntime 은 KserveTornado 가 디폴트이지만, KserveFlask 도 지원하고 있다. 그리고 이는 Predictor Pod 내에서 torchserve와 다른 process로 동작하며(이는 pod 내에 들어가서 프로세스를 확인해보면 확인이 가능하다), client의 request를 받아 torchserve process로 요청을 넘겨주게 된다(kserve가 자동으로 처리함). Pytorch 기본 제공 servingruntime 의 경우는 PyTorch 모델 로드 및 실행을 담당하고 Tornado 또는 Flask 서버에서 호출할 수 있는 추론 API를 제공하는 TorchServe 라이브러리를 사용하여 구현되어 있다.
(7) 그러면 이전 두 포스트에서 만든 .mar 파일과 config.properties를 predicitor pod 안에 잘 넣어줘야 하는데 어떻게 하는가?
위의 Control Plane의 그림을 보면 Storage Initializer 라는게 보인다. 이거는 pod 가 뜰때 먼저 떠서 특정 폴더를 pod내로 마운트 해주고 끝나는데, 이 위치가 바로 /mnt/models 다.
즉, 로컬의 특정 디렉토리에 model-store, config 디렉토리가 있고, 그 아래 이전에 만든 두 파일을 위치시키면 된다!
.
local 의 위치 -> pod 내 /mnt/models
├── config
│ ├── config.properties
├── model-store
│ ├── mnist.mar.
모델 서빙
이제 동작 원리에 대해 알아보았다. 그럼 predictor pod 가 떳다고 가정하고, 공식문서를 보면 curl -v http://sklearn-iris.kserve-test.${CUSTOM_DOMAIN}/v1/models/sklearn-iris:predict -d @./iris-input.json 이런 명령어로 실행된 서비스에 추론 요청을 하는데 도대체 어떻게 이렇게 된 것인가? (이부분도 필자의 공부 수준과 뇌피셜에서 작성되었다. 틀린점을 지적해주시면 감사하겠다.)
TorchServe에서 모델과 서버를 띄우는 방법을 간단히 설명한다.
- 먼저, torchserve 명령어를 실행하면 내부적으로는
ts/model_server.py에서 popen으로 서버가 동작하게 된다. torchserve 내에서 서버 실행 코드. - 이중 모델 서빙은 141번째줄 에서 확인이 가능한데, 실제 동작은 해당 코드 에서 확인 가능하다.
Kserve에서도 모델과 서버를 어떻게 띄우는지 내부 동작을 이해하기 위해 코드 를 보게 되었다.
Kserve가 실행되면 내부적으로는 model_server.py 의 start 함수에서 tornado를 사용해 서버를 띄우게 된다. Kserve 내에서 서버 실행 코드
위의 코드가 모두에게 적용 되는건 아니고, 실제로 기본 제공 pytorch 로 띄운
predictor pod내에서 프로세스를 확인해보면,python /home/model-server/kserve_wrapper/__main__.py해당 명령어가 실행되어 서버가 뜬 것을 확인할 수 있고, 이는 위에서 설명하는 Kserve 내에서 서버 실행 코드와는 다른 코드이다.아무튼.. 첫번째 설명을 이어서 계속 설명해보자면
ModelServer클래스의def create_application부분을 보면 어떻게 띄워질 지 알 수 있는데, 밑의 코드를 보면 어떤 API 에서 어떤 기능이 수행되는지(어떤 Handler가 동작) 알 수 있다. (각각의 내부를 들어가면 tornado.web.RequestHandler 를 상속받은 BaseHandler를 상속받아서 작성되어 있는 것을 알 수 있다)def create_application(self): return tornado.web.Application([ # Server Liveness API returns 200 if server is alive. (r"/", handlers.LivenessHandler), (r"/v2/health/live", handlers.LivenessHandler), (r"/v1/models", handlers.ListHandler, dict(models=self.registered_models)), (r"/v2/models", handlers.ListHandler, dict(models=self.registered_models)), # Model Health API returns 200 if model is ready to serve. (r"/v1/models/([a-zA-Z0-9_-]+)", handlers.HealthHandler, dict(models=self.registered_models)), (r"/v2/models/([a-zA-Z0-9_-]+)/status", handlers.HealthHandler, dict(models=self.registered_models)), (r"/v1/models/([a-zA-Z0-9_-]+):predict", handlers.PredictHandler, dict(models=self.registered_models)), (r"/v2/models/([a-zA-Z0-9_-]+)/infer", handlers.PredictHandler, dict(models=self.registered_models)), (r"/v1/models/([a-zA-Z0-9_-]+):explain", handlers.ExplainHandler, dict(models=self.registered_models)), (r"/v2/models/([a-zA-Z0-9_-]+)/explain", handlers.ExplainHandler, dict(models=self.registered_models)), (r"/v2/repository/models/([a-zA-Z0-9_-]+)/load", handlers.LoadHandler, dict(models=self.registered_models)), (r"/v2/repository/models/([a-zA-Z0-9_-]+)/unload", handlers.UnloadHandler, dict(models=self.registered_models)), ], default_handler_class=handlers.NotFoundHandler)여기까지 필자의 지식 수준에서 kserve 의 동작을 알아보았다.
결론
갑자기 급하게 끝내는 느낌인데... 절대 아니다... 필자의 필력이나, 지식이 부족해서 갑자기 끝나는거 같다 보일뿐... 아무튼!! 결국 모델이 서빙될 때, servingruntime을 보고 모델 서버를 띄우고, 이는 밖에서 REST API로 제어가 가능하다. 마치 프로세스에 떠있는 Torchserve를 REST API로 제어하는 것과 같은데, pod 내의 프로세스로 떠있고, REST API로 제어가 가능한 것은 동일하다.
아무튼... Kserve를 이용하면 모델을 서빙하고, REST API로 관리할 수 있고, 프로메테우스로 metric도 볼 수 있고, canary 같은 기능도 사용할 수 있다.
뭔가... 더 써보고 더 명확하게 전달 할 수 있는 포인트가 있으면 다시 글을 작성해보도록 하겠다... 그럼 이만...
'IT > MLOps' 카테고리의 다른 글
| [MLOps] 2. KServe-Torchserve 를 위한 TorchServe 사용법 (0) | 2023.05.03 |
|---|---|
| [MLOps] 1. KServe-Torchserve 를 위한 TorchModelArchiver 서빙 준비 (0) | 2023.05.03 |
댓글